Python 3開發網絡爬蟲(一)
選擇Python版本
有2和3兩個版本, 3比較新, 聽說改動大. 根據我在知乎上搜集的觀點來看, 我還是傾向於使用”在趨勢中將會越來越火”的版本, 而非”目前已經很穩定而且很成熟”的版本. 這是個人喜好, 而且預測不一定準確. 但是如果Python3無法像Python2那麼火, 那麼整個Python語言就不可避免的隨著時間的推移越來越落後, 因此我想其實選哪個的最壞風險都一樣, 但是最好回報卻是Python3的大. 其實兩者區彆也可以說大也可以說不大, 最終都不是什麼大問題. 我選擇的是Python 3.
選擇參考資料
由於我是一邊學一邊寫, 而不是我完全學會了之後才開始很有條理的寫, 所以參考資料就很重要(本來應該是個人開發經驗很重要, 但我是零基礎).
- Python官方文檔
- 知乎相關資料(1) 這篇非常好, 通俗易懂的總覽整個Python學習框架.
- 知乎相關資料(2)
寫到這裡的時候, 上麵第二第三個鏈接的票數第一的回答已經看完了, 他們提到的有些部分(比如爬行的路線不能有回路)我就不寫了。
一個簡單的偽代碼
以下這個簡單的偽代碼用到了set和queue這兩種經典的數據結構, 集與隊列. 集的作用是記錄那些已經訪問過的頁麵, 隊列的作用是進行廣度優先搜索.
queue Q
set S
StartPoint = "http://jecvay.com"
Q.push(StartPoint) # 經典的BFS開頭
S.insert(StartPoint) # 訪問一個頁麵之前先標記他為已訪問
while (Q.empty() == false) # BFS循環體
T = Q.top() # 並且pop
for point in PageUrl(T) # PageUrl(T)是指頁麵T中所有url的集合, point是這個集合中的一個元素.
if (point not in S)
Q.push(point)
S.insert(point)
這個偽代碼不能執行, 我覺得我寫的有的不倫不類, 不類Python也不類C++.. 但是我相信看懂是冇問題的, 這就是個最簡單的BFS結構. 我是看了知乎裡麵的那個偽代碼之後, 自己用我的風格寫了一遍. 你也需要用你的風格寫一遍.
這裡用到的Set其內部原理是采用了Hash表, 傳統的Hash對爬蟲來說占用空間太大, 因此有一種叫做Bloom Filter的數據結構更適合用在這裡替代Hash版本的set. 我打算以後再看這個數據結構怎麼使用, 現在先跳過, 因為對於零基礎的我來說, 這不是重點.
代碼實現(一): 用Python抓取指定頁麵
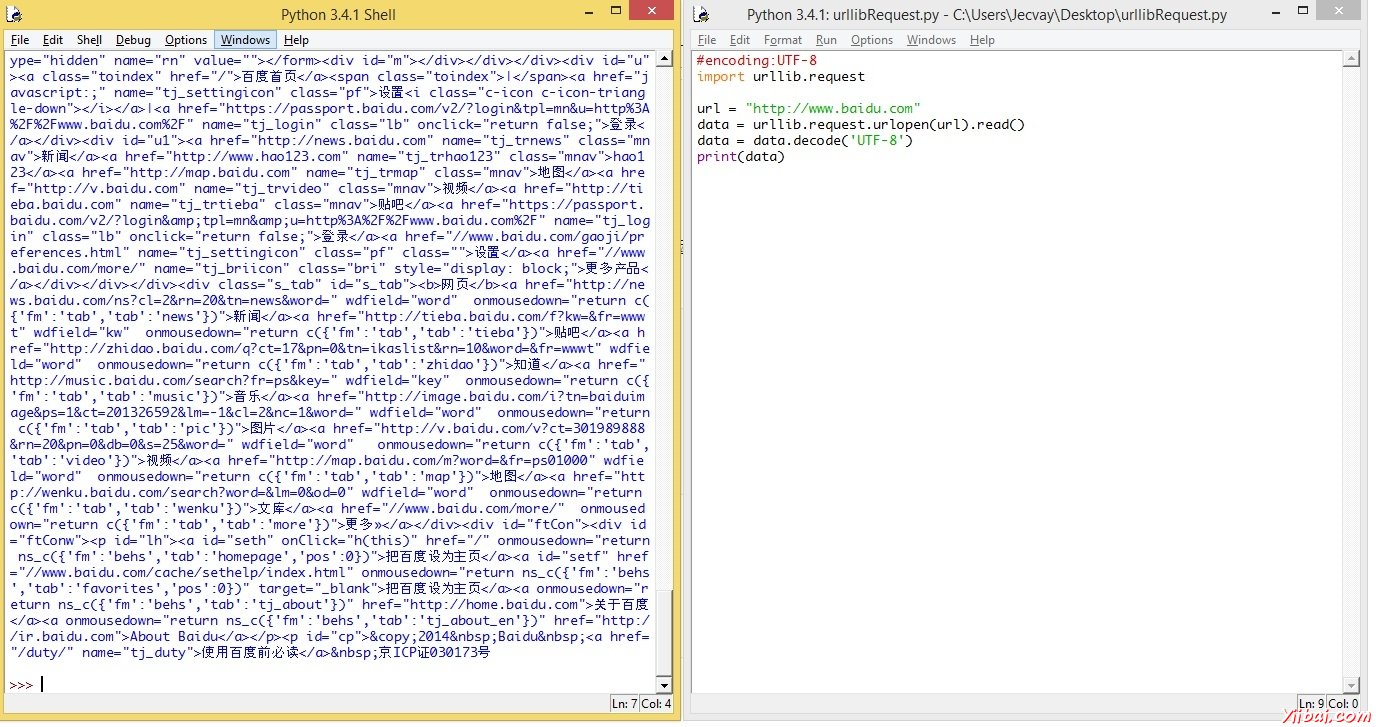
我使用的編輯器是Idle, 安裝好Python3後這個編輯器也安裝好了, 小巧輕便, 按一個F5就能運行並顯示結果. 代碼如下:
#encoding:UTF-8
import urllib.request
url = "http://www.baidu.com"
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)
urllib.request是一個庫, 隸屬urllib. 點此打開官方相關文檔. 官方文檔應該怎麼使用呢? 首先點剛剛提到的這個鏈接進去的頁麵有urllib的幾個子庫, 我們暫時用到了request, 所以我們先看urllib.request部分. 首先看到的是一句話介紹這個庫是乾什麼用的:
The urllib.request module defines functions and classes which help in opening URLs (mostly HTTP) in a complex world — basic and digest authentication, redirections, cookies and more.
然後把我們代碼中用到的urlopen()函數部分閱讀完.
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False)
重點部分是返回值, 這個函數返回一個 http.client.HTTPResponse 對象, 這個對象又有各種方法, 比如我們用到的read()方法, 這些方法都可以根據官方文檔的鏈接鏈過去. 根據官方文檔所寫, 我用控製台運行完畢上麵這個程序後, 又繼續運行如下代碼, 以更熟悉這些亂七八糟的方法是乾什麼的.
>>> a = urllib.request.urlopen(full_url)
>>> type(a)
<class ‘http.client.HTTPResponse’>>>> a.geturl()
‘http://www.baidu.com/s?word=Jecvay’>>> a.info()
<http.client.HTTPMessage object at 0x03272250>>>> a.getcode()
200
代碼實現(二): 用Python簡單處理URL
如果要抓取百度上麵搜索關鍵詞為Jecvay Notes的網頁, 則代碼如下
import urllib
import urllib.request
data={}
data['word']='Jecvay Notes'
url_values=urllib.parse.urlencode(data)
url="http://www.baidu.com/s?"
full_url=url+url_values
data=urllib.request.urlopen(full_url).read()
data=data.decode('UTF-8')
print(data)
data是一個字典, 然後通過urllib.parse.urlencode()來將data轉換為 ‘word=Jecvay+Notes’的字符串, 最後和url合並為full_url, 其餘和上麵那個最簡單的例子相同. 關於urlencode(), 同樣通過官方文檔學習一下他是乾什麼的. 通過查看
- urllib.parse.urlencode(query, doseq=False, safe=”, encoding=None, errors=None)
- urllib.parse.quote_plus(string, safe=”, encoding=None, errors=None)
大概知道他是把一個通俗的字符串, 轉化為url格式的字符串。
( 轉載自: Jecvay Notes )